コンジョイント分析詳細
書籍「製品開発に役立つ感性・官能評価データ解析−Rを利用して−」より引用
検定表、数表は省略しています。
以下の例の手順および数値の詳細は書籍でご確認ください。
また、表示の関係から、数式が正しく表示されていない部分があります。
J-SEMS.PROで以下の解析を行うことができます。
手法
マーケッティング・リサーチの分野では、商品を特徴付ける要因を属性といい、その属性の具体的な内容を水準と呼ぶ。ここでは、それぞれの属性の中から、様々な要因をピックアップし、それらの要因を組み合わせて、仮の商品コンセプトを作り、それらを消費者に順位付けしてもらう。このようにして得られた順位データを元にして、各属性と各水準の効用を算出し、最適な商品コンセプトを作り出すことを目指すものである。
例
<実施例>男性用の腕時計のデザインで、消費者の購買に最も影響を及ぼす属性はどれか

ここで知りたい情報は
- 各属性において水準1 と2のどちらが消費者に支持されるか。
- 消費者の購買に最も影響を及ぼす属性はどれか。
L8直交配列表を用いて、解析結果の質を保持しつつ、順位付けの回数を減らす。
L8直交配列表

L8 直交配列表に従って、腕時計の属性・水準を割り付けると下記の表のようになる。
L8 直交配列表に従った腕時計の属性・水準の割り付け
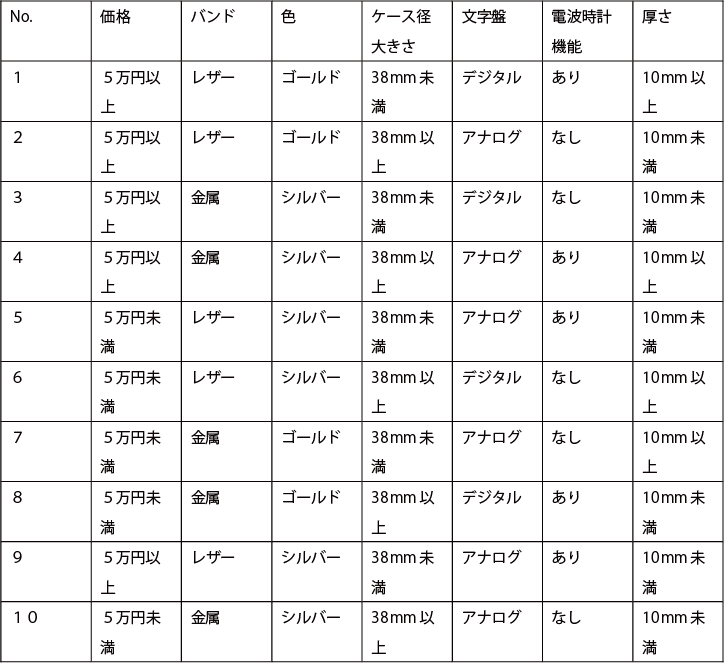
No.1からNo.8までの8 枚のコンジョイントカードを作成し、さらに、分析結果の信頼性を検証するためにホールドアウトカードを2 枚作成する。合わせて10 枚のカードに対して、各パネリストは、どのカードの製品が一番買いたくて、次はどれかというように、すべてのカードについて、1位から10位までの順位付けをする。
なお、ホールドアウトカードは、7つの属性のすべての組み合わせ数128からL8直交配列表の組み合わせ8を引いた120 の組み合わせの中からランダムに選ぶ。
結果の分析
前表の直交表に割り当てた1と2の数字は連続量とみなし、1を-1、2を1に変換して、その7つの変数を説明変数とし、1 位から10 位までの順位データ(これも連続量とみなす)を目的変数とする重回帰分析を行う。なお、分析結果の信頼性を検証するためのN0.9とNo.10の2枚のカードは分析を行う際には用いない。分析は、RやExcelのデータ分析ツールで行う。
データの例

重回帰分析によって得られた偏回帰係数とy切片に着目して、以下の分析を進める。
計算例
ステップ1:
≪重回帰分析の結果≫
y切片:6.325
偏回帰係数:
価格 :0.12
バンド :-0.23
色 :-0.02
大きさ :0.18
文字盤 :-0.05
電波時計機能 :-0.16
厚さ :0.13
ステップ2:各属性、各水準の効用値、範囲、分散、分散の寄与率を求める。
各属性、各水準の効用値、範囲、分散、分散の寄与率
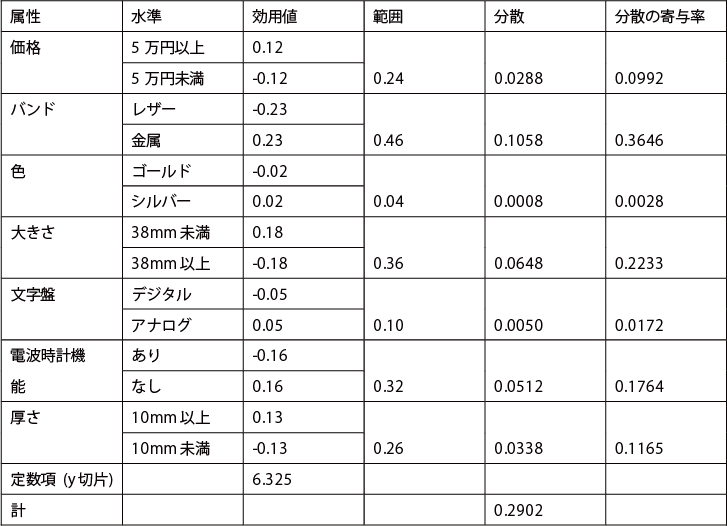
1)各属性の第1水準の効用値には、求めた偏回帰係数の値が入る。
2)各属性の第2水準の効用値には、第1水準の効用値の正負の符号が反転した値が入る。
3)各属性の第1水準と第2水準の効用値の差の絶対値を求め、それを各属性の範囲とする。
4)各属性の効用値の分散を求める。分散は、” ͈ 2 2Í で求めることができる。
5)各属性の分散を分散の合計で除して、各属性の分散の寄与率を求める。
ステップ3:コンジョイントカードの平均順位と予測順位の比較により、解析結果の信頼性を検討する
1)全パネリストのデータから、カード1〜8の平均順位を求める。
2)カード1〜8の予測順位を求める。各カードの予測順位は、下記の式による。
予測順位=定数項(y切片)−(各属性における該当する水準番号の効用値の合計)例えば、カード1の予測順位は、7 つの属性とも該当する水準番号は、すべて1 番なので、
6.325-(0.12-0.23-0.02+0.18-0.05-0.16+0.13)=6.295 となる。
3)平均順位と予測順位の差を検討する。両者の差が、2 以下であれば、信頼性は満たされたとする。
ステップ4:ホールドアウトカードの平均順位と予測順位との比較により、解析結果の信頼性を検討する
1)全パネリストのデータから、カード9〜10の平均順位を求める。
2)カード9〜10の予測順位を求める。予測順位は、コンジョイントカードの場合と同じで、下記の式による。
予測順位=定数項(y切片)−(各属性における該当する水準番号の効用値の合計)
3)平均順位と予測順位の差を検討する。両者の差が、2 以下であれば、信頼性は満たされたとする。